Relacyjny Rekord Aktywny
Dotychczas zobaczyliśmy jak używać Rekordu Aktywnego (AR) aby wybierać dane z jednej tabeli bazodanowej. W tej sekcji opiszemy jak używać AR aby złączyć kilka powiązanych tabel baz danych i zwrócić połączony zbiór danych.
W celu używania relacyjnego AR, rekomendujemy aby zadeklarować ograniczenia podstawowego klucza obcego dla tabel, które potrzebujemy złączać. Ograniczenia przyczynią się do zachowania spójności i integralności danych relacyjnych.
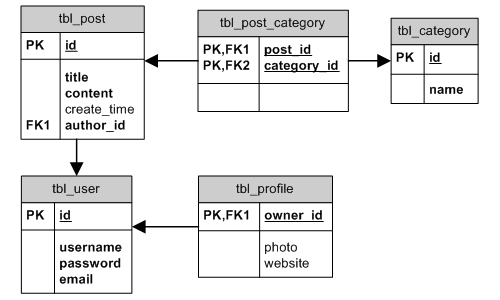
Dla uproszczenia, będziemy używali schematu bazy danych pokazanego na następnym diagramie zależności encji (ER) celem zilustrowania przykładów w tej sekcji.
Diagram ER
Info: Wsparcie dla ograniczeń kluczy obcych różni sie dla różnych DBMS. SQLite < 3.6.19 nie wspiera ograniczeń kluczy obcych, lecz wciąż możesz deklarować ograniczenia, podczas tworzenia tabel. Silnik MyISAM w ogóle nie posiada wsparcia dla kluczy obcych.
Deklarowanie relacji
Zanim użyjemy AR aby wykonać relacyjne zapytanie, musimy powiedzieć AR jak jedna klasa AR jest powiązana z drugą.
Relacja pomiędzy dwoma klasami AR jest bezpośrednio związana z relacją pomiędzy
tabelami bazy danych reprezentowanych przez klasę AR. Z punktu widzenia bazy danych
relacja pomiędzy dwoma tabelami A i B może występować w 3 wariantach:
jeden-do-wielu (ang. one-to-many; np. tbl_user i tbl_post), jeden-do-jednego (ang. one-to-one;
np. tbl_user i tbl_profile) oraz wiele-do-wielu (ang. many-to-many; np. tbl_category i tbl_post).
W AR występują cztery rodzaje relacji:
BELONGS_TO(należy do): jeśli relacja pomiędzy tabelą A i B to jeden-do-jednego, wtedy B należy do A (np. posttbl_postnależy do użytkownikatbl_user);HAS_MANY(posiada wiele): jeśli relacja pomiędzy tabelą A i B to jeden-do-wielu wtedy A ma wiele B (np. użytkowniktbl_userma wiele postówtbl_post);HAS_ONE(posiada jedną): to jest specjalny przypadek relacjiHAS_MANYgdzie A posiada co najwyżej jedno B (np. użytkowniktbl_userma co najwyżej jeden profiltbl_profile);MANY_MANY(wiele do wielu): odpowiada relacji bazodanowej wiele-do-wielu. Aby rozbić relację wiele-do-wielu na jeden-do-wielu potrzebna jest tablica asocjacyjna, gdyż wiele DBMS nie wspiera bezpośrednio relacji wiele-do-wielu. W naszym przykładzie schemat bazy danychtbl_post_categoryzostanie użyty w tym celu. W terminologii AR, możemy wytłumaczyć relację wiele-do-wielu jako kombinacjęBELONGS_TOorazHAS_MANY. Na przykład, posttbl_postnależy do wielu kategoriitbl_categorya kategoriatbl_categoryposiada wiele postówtbl_post.
Deklarowanie relacji w AR wymaga nadpisania metody relations() z CActiveRecord. Metoda zwraca tablicę konfiguracji relacji. Każdy element tablicy reprezentuje pojedynczą relację zapisaną w następującym formacie:
gdzie NazwaZmiennej jest nazwą relacji; TypRelacji specyfikuje typ relacji i posiada
jedną z czterech stałych wartości:
self::BELONGS_TO, self::HAS_ONE, self::HAS_MANY oraz
self::MANY_MANY; NazwaKlasy jest nazwą klasy AR powiązanej z tą klasą; oraz
KluczObcy określa klucz(e) obcy(e) powiązane z tą relacją. Dodatkowe opcje mogą być
określone na końcu każdej relacji (więcej szczegółów w dalszej części).
Następujący kod pokazuje jak możemy zadeklarować relację dla klasy użytkownika User
oraz postu Post.
Info: Klucz obcy może być kluczem złożonym, zawierającym dwie lub więcej kolumn. W takim przypadku, powinniśmy złączyć nazwy kolumn dla kluczy obcych rozdzielając przecinkiem lub przekazać je pod postacią tablicy, np. array('klucz1','klucz2'). W przypadku gdy potrzebujesz zdefiniować niestandardowe przypisanie PK->FK, możesz zdefiniować ją jako tablicę array('fk'=>'pk'). Dla kluczy złożonych będzie to tablica array('fk_c1'=>'pk_c1','fk_c2'=>'pk_c2'). Dla relacji typu
MANY_MANY, nazwa tablicy asocjacyjnej musi również być określona w kluczu obcym. Na przykład, relacja kategoriicategorieswtbl_postjest określona przez klucz obcytbl_post_category(post_id, category_id).
Deklaracja relacji w klasie AR domyślnie dodaje właściwość do klasy
dla każdej relacji. Po tym jak zapytanie relacyjne jest wykonywane, odpowiadająca
właściwość będzie wypełniona odpowiadającymi instancjami AR. Na przykład, jeśli $author
reprezentuje instancję AR User, możemy użyć $author->posts aby dostać się do
powiązanych instancji Post.
Wykonywanie zapytań relacyjnych
Najprostszym sposobem wykonania relacyjnego zapytania jest odczytanie relacyjnej właściwości instancji AR. Jeśli właściwość nie była wcześniej odczytywana, relacyjne zapytanie zostanie zainicjalizowane za pomocą którego złączymy dwie połączone ze sobą tabele i odfiltrujemy dane przy użyciu klucza głównego aktualnej instancji AR. Wynik zapytania będzie zapisany we właściwości jako instancja(e) powiązanej klasy AR. Jest to znane jako technika opóźnionego ładowania (ang. lazy loading approach), np. zapytanie relacyjne jest wykonywane tylko wtedy, gdy powiązane obiekty są odczytywane po raz pierwszy. Poniższy przykład pokazuje jak używać tej techniki:
Info: Jeśli nie istnieją żadne powiązane instancje dla relacji, odpowiednie właściwości mogą być pustą tablicą bądź wartością null. Dla relacji
BELONGS_TOorazHAS_ONEwynikiem jest wartość null; dlaHAS_MANYorazMANY_MANYjest to pusta tablica.
Zauważ, że relacje HAS_MANY oraz MANY_MANY zwracają tablicę obiektów, dlatego
będziesz musiał przejść w pętli przez zwrócony wynik, jeśli będziesz chciał uzyskać dostęp
do jakiejkolwiek właściwości obiektu. W przeciwnym przypadku, możesz uzyskać błąd: "Próbujesz
skorzystać z właściwości elementu nie będącego obiektem" (ang. "Trying to get property of non-object" errors).
Technika opóźnionego ładowania jest bardzo poręczna w użyciu, ale nie zawsze jest wydajna
we wszystkich scenariuszach. Dla przykładu, jeśli chcemy uzyskać dostęp do informacji o autorze dla
N postów, używając techniki opóźnionego ładowania wykonamy N zapytań z użyciem join.
W tych warunkach powinniśmy uciec się do tak zwanej techniki zachłannego ładowania
(ang. eager loading approach).
Technika zachłannego ładowania zwraca powiązane instancje AR razem z główną(ymi) instancją(ami) AR. Osiągamy to poprzez użycie metody with() razem z jedną z metod AR find lub findAll. Na przykład,
Powyższy kod zwróci tablicę instancji Post. W odróżnieniu od techniki leniwego ładowania
właściwość author w każdej instancji Post jest już wypełniona odpowiednią instancją
User przed jej pierwszym odczytaniem. Zamiast wywoływania zapytania z join dla
każdego posta, technika zachłannego ładowania zwraca wszystkie posty wraz z autorami
za pomocą jednego zapytania z join!
Możemy używać jednocześnie wielu nazw relacji w metodzie with() a technika zachłannego łączenia dostarczy nam je z powrotem za jednym razem. Na przykład, następujący kod zwróci posty razem z ich autorami oraz kategoriami:
Możemy również korzystać z zagnieżdżonych zachłannych ładowań. Zamiast listy nazw relacji, przekazujemy w postaci hierarchicznej nazwy relacji do metody with() w następujący sposób:
Powyższy przykład zwróci wszystkie posty razem z ich autorami oraz kategoriami. Zwróci również dla każdego autora profil oraz posty.
Zachłanne ładowanie może zostać również wywołane poprzez określenie właściwości CDbCriteria::with w następujący sposób:
lub
Wykonywanie relacyjnych zapytań bez konieczności zwracania powiązanych modeli
Czasami potrzebujemy wykonać zapytanie relacyjne ale nie potrzebujemy danych z powiązanych
modeli. Załóżmy, że mamy użytkowników User, którzy utworzyli wiele postów Post.
Posty mogą być zarówno opublikowane jak i zapisane jako szkice. O tym stanie decyduje pole
published w modelu postu. Chcielibyśmy więc otrzymać listę wszystkich użytkowników,
którzy opublikowali posty ale nie jesteśmy zainteresowani treścią tych postów. Możemy
to osiągnąć w następujący sposób:
Opcje zapytań relacyjnych
Wspominaliśmy, że dodatkowe opcje mogą być określone w deklaracji relacji. Opcje te zapisane jako pary nazw i wartości używane są w celu dostosowania do własnych potrzeb zapytań relacyjnych. Poniżej znajdziemy ich zestawienie.
select: lista kolumn, które będą zwrócone dla powiązanej klasy AR. Domyślną wartością jest '*', oznaczająca wszystkie kolumny. Nazwy kolumn
do których się odwołujemy w tej opcji powinny zostać ujednoznacznione.condition: klauzulaWHERE. Domyślnie pusta. Nazwy kolumn
do których się odwołujemy w tej opcji powinny zostać ujednoznacznione.params: parametry, które zostaną przypięte do wygenerowanego wyrażenia SQL. Powinny zostać przekazane jako tablica par nazwa-wartość.on: klauzulaON. Warunki określone tutaj będą dołączone do warunków złączenia przy użyciu operatoraAND. Nazwy kolumn do których się odwołujemy w tej opcji powinny zostać ujednoznacznione.order: klauzulaORDER BY. Nazwy kolumn do których się odwołujemy w tej opcji powinny zostać ujednoznacznione.with: lista obiektów potomnych, które powinny zostać załadowane wraz z tym obiektem. Należy pamiętać, że niewłaściwe użycie tej opcji może skutkować utworzeniem nigdy niekończącej się pętli.joinType: typ złączenia dla relacji. Domyślna wartość toLEFT OUTER JOIN.alias: alias dla tablicy powiązanej z relacją. Domyślnie posiada wartość null, co oznacza iż alias tablicy jest taki sam jak nazwa relacji.together: używana jeśli tabele powiązane mają zostać zmuszone do połączenia się razem z główną tabelą oraz pozostałymi tabelami. Opcja ta ma znaczenie dla relacjiHAS_MANYorazMANY_MANY. Jeśli opcja ta ma wartość ustawioną jako false, wtedy tabela związana z relacjąHAS_MANYlubMANY_MANYzostanie połączona z tabelą główną w osobnym zapytaniu SQL, co może zwiększyć ogólną wydajność zapytania, gdyż zwracana jest mniejsza ilość powtarzających się danych. Jeśli ta opcja posiada wartość true, powiązana tabela będzie zawsze dołączona do pierwszej tabeli za pomocą pojedyńczego zapytania SQL, nawet jeśli pierwsza tabela jest stronicowana. Jeśli ta opcja nie jest ustawiona, powiązana tabela będzie dołączona do pierwszej tabeli za pomocą pojedynczego zapytania SQL tylko wtedy kiedy pierwsza tabela nie jest stronicowana. Aby uzyskać więcej szczegółow, zobacz do działu "Wydajność zapytań relacyjnych".join: dodatkowa klauzulaJOIN. Domyślnie pusta. Opcja ta jest dostępna od wersji 1.1.3.group: klauzulaGROUP BY. Domyślnie pusta. Nazwy kolumn
do których się odwołujemy w tej opcji powinny zostać ujednoznacznione.having: klauzulaHAVING. Domyślnie pusta. Nazwy kolumn
do których się odwołujemy w tej opcji powinny zostać ujednoznacznione.index: nazwa kolumny, której wartość powinna zostać użyta jako klucz tablicy, która zawiera powiązane obiekty. Bez ustawienia tej opcji, tablica obiektów powiązanych będzie używała indeksu całkowitoliczbowego rozpoczynającego się od liczby zero. Opcja ta może zotać ustawiona tylko dla relacjiHAS_MANYorazMANY_MANY.scopes: możliwe do zastosowania zakresy. W przypadku pojedynczego zakresu, należy używać tej opcji następująco'scopes'=>'nazwaZakresu', zaś w przypadku wielu zakresów'scopes'=>array('nazwaZakresu1','nazwaZakresu2'). Opcja ta jest dostępna od wersji 1.1.9.
Dodatkowo, następujące opcje są dostępne dla wybranych relacji podczas opóźnionego ładowania:
limit: ogranicza ilość zwracanych wierszy. Opcja ta nie ma zastosowania dla relacjiBELONGS_TO.offset: offset dla zwracanych wierszy. Opcja ta nie ma zastosowania dla relacjiBELONGS_TO.through: nazwa relacji modelu, która będzie używana jako pomost podczas zwracania powiązanych danych. Opcja ta może zostać ustawiona tylko dla relacjiHAS_ONEorazHAS_MANY. Opcja ta jest dostępna od wersji 1.1.7.
Poniżej zmodyfikujemy deklarację relacji posts w klasie User poprzez wybranie części z powyższych opcji.
Teraz jeśli odczytamy $author->posts, powinniśmy otrzymać autorów postów
posortowanych malejąco wg czasu ich utworzenia. Każda instancja postu będzie
również posiadała wczytaną odpowiadającą jej kategorię.
Ujednoznacznianie nazw kolumn
Kiedy nazwa kolumny pojawia się w dwóch lub więcej tabelach, które będą łączone należy ją ujednoznacznić (rozróżnić). Robi się to poprzedzając nazwę kolumny prefiksem będącym aliasem nazwy tabeli.
Domyślnie, w relacyjnych zapytaniach AR alias nazwy dla głównej tabeli ustalony jest
jako t, gdy zaś alias nazwy dla tabeli relacyjnej jest taki sam jak odpowiadająca.
Na przykład, w kolejnym wyrażeniu aliasem nazwy dla postu Post oraz komentarza Comment
są odpowiednio t oraz comments:
Załóżmy teraz, że zarówno Post oraz Comment posiadają kolumnę czas utworzenia create_time
postu lub komentarza i chcemy pobrać posty razem z ich komentarzami, najpierw sortując po czasie
utworzenia postów a następnie po czasie utworzenia komentarzy. Potrzebujemy ujednoznacznić
kolumnę czasu utworzenia create_time w następujący sposób:
Dynamiczne opcje pytań relacyjnych
Możemy używać dynamicznych opcji zapytań relacyjnych zarówno w metodzie
with() jak i opcji with. Dynamiczne opcje nadpiszą istniejące
opcje tak jak zostało to określone w metodzie relations().
Na przykład, dla powyższego modelu User, jeśli chcemy używać techniki zachłannego ładowania
aby zwrócić posty należące do autora sortujące jest rosnąco
(opcja order w specyfikacji relacji jest malejąca), możemy zrobić to następująco:
Opcje dynamicznych zapytań mogą być również używane dla leniwego ładowania
w celu wykonywania zapytań relacyjnych. Aby to zrobić, powinniśmy wywołać metodę, której nazwa jest identyczna
z nazwą relacji oraz przekazać opcje dynamicznego zapytania jako parametr metody.
Na przykład, następujący kod zwróci posty użytkownika, których status wynosi 1:
Wydajność relacyjnych zapytań
Jak opisaliśmy powyżej, zachłanne ładowanie jest używane w scenariuszu, gdy potrzebujemy otrzymać
dostęp do wielu powiązanych obiektów. Generuje ono duże, złożone zapytanie SQL
poprzez połączenie wszystkich potrzebnych tabel. Duże zapytanie SQL
jest preferowane w wielu przypadkach, ponieważ upraszcza filtrowanie
oparte na kolumnie w relacyjnych tabelach. Jednakże może ono być
nieefektowne w niektórych przypadkach.
Rozważmy przypadek, gdzie potrzebujemy znaleźć ostatnie posty razem z ich komentarzami. Zakładając, że każdy post posiada 10 kometarzy, używanie pojedynczego, dużego zapytania SQL, zwróci wiele powtarzających się danych postów, ze względu na to, że każdy post będzie powtórzony dla każdego posiadanego komentarza. Z nowym podejściem potrzebujemy wywołać dwa zapytanie SQL. Korzyścią z tego płynącą jest brak redundancji w zwróconych rezultatach zapytania.
Zatem, które podejście jest bardziej wydajne? Nie ma jednoznacznej odpowiedzi. Wywołanie pojedynczego, dużego zapytania SQL może być bardziej wydajne ponieważ powoduje mniejsze obciążenie DBMS podczas parsowania i wykonywania zapytania SQL. Z drugiej strony używając pojedynczego zapytania SQL, mamy w końcu więcej redundantnych danych i w ten sposób potrzebujemy więcej czasu by je odczytać i przetworzyć.
Z tego powodu Yii dostarcza opcję zapytania together tak, by można było wybierać pomiędzy
oboma podejściami w zależności od potrzeb. Domyślnie Yii używa ładowania zachłannego, np.
tworzy jedno zapytanie SQL, z wyłączeniem przypadków, kiedy stosujemy dla głównego modelu LIMIT.
Możemy ustawić opcję together na true w deklaracji relacji by wymusić pojedyncze wyrażenie SQL
nawet gdy używamy konstrukcji z LIMIT. Ustawienie tej opcji na false spowoduje dla niektórych tabel
łączenie ich w oddzielnych wyrażeniach SQL. Na przykład, w celu używania osobnego wyrażenia SQL
odpytującego o ostatni post wraz z komentarzem, możemy zadeklarować relację comments w klasie Post następująco:
Możemy również dynamicznie ustawić tą opcję kiedy wykonujemy zachłanne ładowanie:
Zapytania statystyczne (ang. Statistical Query)
Poza zapytaniami relacyjnymi opisanymi powyżej, Yii wspiera również tak zwane zapytania statystyczne (lub zapytania agregacyjne). Odnoszą się one do uzyskiwania agregowanych
informacji o powiązanych obiektach, takich jak liczba komentarzy dla każdego postu, średnia ocena dla każdego produktu, itp. Zapytania statystyczne mogą być wykonywane dla obiektów
wskazywanych w relacji HAS_MANY (np. post ma wiele komentarzy) lub MANY_MANY (np. post należy do wielu kategorii a kategoria ma wiele postów).
Wykonywania zapytań statystycznych jest bardzo podobne do wykonywania opisanych wcześniej zapytań relacyjnych. Najpierw musimy zdefiniować zapytanie statystyczne w metodzie relations() klasy CActiveRecord tak jak robimy to dla zapytań relacyjnych.
Powyżej zadeklarowaliśmy dwa zapytania statystyczne: commentCount oblicza ilość komentarzy należących do postu a categoryCount oblicza ilość kategorii do których należy post.
Zauważ, że relacja pomiędzy Post a Comment jest relacją HAS_MANY, podczas gdy relacja pomiędzy Post a Category jest relacją MANY_MANY
(wraz z łączącą je tabelą post_category). Jak możemy zauważyć, deklaracja jest bardzo podobna do tych z relacji opisywanych we wcześniejszych podpunktach.
Jedyną różnicą jest to, że typem relacji jest tutaj STAT.
Przy użyciu powyższej deklaracji możemy otrzymać ilość komentarzy dla postu przy użyciu wyrażenia $post->commentCount. Jeśli użyjemy tej właściwości po raz pierwszy,
wyrażenie SQL zostanie wywołane w ukryciu w celu uzyskania pożądanego rezultatu. Jak już wiemy, jest to tak zwane leniwe ładowanie.
Możemy również używać zachłannego ładowania jeśli chcemy uzyskać ilość komentarzy dla wielu postów.
Powyższe wyrażenie wykona trzy zapytania SQL aby zwrócić wszystkie posty razem z policzonymi komentarzami oraz policzonymi kategoriami. Używając podejścia leniwego ładowania
skończylibyśmy z 2*N+1 zapytaniami SQL, gdzie N to ilość postów.
Domyślnie zapytanie statystyczne użyje wyrażenia COUNT do obliczeń (i w ten sposób policzymy komentarze oraz kategorie w powyższych przykładach). Możemy je dostosować
do własnych potrzeb poprzez określenie dodatkowych opcji podczas deklarowania go w metodzie relations(). Podsumowanie dostępnych opcji znajduje się poniżej.
select: wyrażenie statystyczne. DomyślnieCOUNT(*), co oznacza liczenie obiektów potomnych.defaultValue: wartość jaka będzie przypisana do tych rekordów, dla których nie zostaną zwrócone rezultaty zapytania statystycznego. Na przykład, jeśli post nie posiada żadnych komentarzy, jegocommentCountotrzyma tą wartość. Wartość domyślna dla tej opcji to zero.condition: klauzulaWHERE. Domyślnie jest pusta.params: parametry, które mają zostać związane z wygenerowanym zapytaniem SQL. Powinny być one przekazane jako tablica par nazwa-wartość.order: klauzulaORDER BY. Domyślnie jest pusta.group: klauzulaGROUP BY. Domyślnie jest pusta.having: klauzulaHAVING. Domyślnie jest pusta.
Relacyjne zapytania z nazwanymi podzbiorami
Relacyjne zapytania mogą być wykonywane w połączeniu z nazwanymi zbiorami. Rozróżniamy dwa przypadki. W pierwszym, nazwany podzbiór stosowany jest do głównego modelu. W drugim, nazwany podzbiór stosowany jest do powiązanego modelu.
Następujący kod pokazuje, jak zastosować nazwane podzbiory do głównego modelu.
Przypomina to bardziej nierelacyjne zapytania. Jedyna różnica polega na tym, że mamy wywołanie metody with()
po łańcuchu wywołań nazwanych podzbiorów. Zapytanie zwróci ostatnio opublikowane posty wraz z ich komentarzami.
Następujący kod pokazuje, jak zastosować nazwane podzbiory do modelu powiązanego.
Powyższe zapytanie zwróci wszystkie posty wraz z zatwierdzonymi komentarzami. Zauważ, że comments jest referencją
do nazwy relacji, a recently oraz approved referuje do dwóch nazwanych podzbiorów w klasie modelu Comment.
Nazwa relacji oraz nazwane podzbiory powinny być rozdzielone dwukropkiem.
Nazwane podzbiory mogą również zostać zdefiniowane w opcji with reguły relacyjnej zadeklarowanej
w CActiveRecord::relations(). W następnym przykładzie, jeśli odczytamy $user->posts,
zwróci nam wszystkie zatwierdzone komentarze (approved) postu.
php class User extends CActiveRecord { public function relations() { return array( 'posts'=>array(self::HAS_MANY, 'Post', 'author_id', 'with'=>'comments:approved'), ); } }
// lub od 1.1.7 class User extends CActiveRecord { public function relations() { return array( 'posts'=>array(self::HAS_MANY, 'Post', 'author_id', 'with'=>array( 'comments'=>array( 'scopes'=>'approved' ), ), ), ); } }
php $users=User::model()->findAll(array( 'with'=>array( 'posts'=>array( 'scopes'=>array( 'rated'=>5, ), ), ), ));
php 'comments'=>array(self::HAS_MANY,'Comment',array('key1'=>'key2'),'through'=>'posts'),
php class Group extends CActiveRecord { ... public function relations() { return array( 'roles'=>array(self::HAS_MANY,'Role','group_id'), users'=>array(self::HAS_MANY,'User',array('user_id'=>'id'),'through'=>'roles'), 'comments'=>array(self::HAS_MANY,'Comment',array('id'=>'user_id'),'through'=>'users'), ); } }
php // zwróć wszystkie grupy wraz z odpowiadającymi im użytkownikami $groups=Group::model()->with('users')->findAll();
// zwróć wszystkie grupy wraz z odpowiadającymi im użytkownikami i rolami $groups=Group::model()->with('roles','users')->findAll();
// zwróć wszystkich użytkowników i role gdzie ID grupy to 1 $group=Group::model()->findByPk(1); $users=$group->users; $roles=$group->roles;
// zwróć wszystkie komentarze gdzie ID grupy to 1 $group=Group::model()->findByPk(1); $comments=$group->comments;
php class User extends CActiveRecord { ... public function relations() { return array( 'profile'=>array(self::HAS_ONE,'Profile','user_id'), 'address'=>array(self::HAS_ONE,'Address',array('id'=>'profile_id'),'through'=>'profile'), ); } }
php // zwróć adres użytkownika o ID równym 1 $user=User::model()->findByPk(1); $address=$user->address;
php class User extends CActiveRecord { ... public function relations() { return array( 'mentorships'=>array(self::HAS_MANY,'Mentorship','teacher_id','joinType'=>'INNER JOIN'), 'students'=>array(self::HAS_MANY,'User',array('student_id'=>'id'),'through'=>'mentorships','joinType'=>'INNER JOIN'), ); } }
php // zwróć wszystkich studentów prowadzonych przez nauczyciela o ID równym 1 $teacher=User::model()->findByPk(1); $students=$teacher->students; ~~~