關聯式 Active Record
我們已經瞭解了怎樣使用 Active Record (AR) 從單個資料表中獲取資料。在本節中,我們講解怎樣使用 AR 連接多個相關資料表並取回關聯後的資料集。
為了使用關聯式 AR,我們建議在需要關聯的表中定義主鍵-外鍵約束。這些約束可以幫助保證相關資料的一致性和完整性。
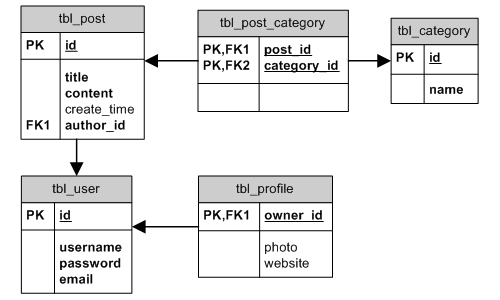
為簡單起見,我們使用如下所示的實體-關係(ER)圖中的資料結構示範此節中的例子。
ER Diagram
訊息: 對外鍵約束的支援在不同的 DBMS 中是不一樣的。SQLite < 3.6.19 不支援外鍵約束,但你依然可以在建立資料表時宣告約束。
宣告關係
在我們使用 AR 執行關聯查詢之前,我們需要讓 AR 知道一個 AR 類別是怎樣關聯到另一個的。
兩個 AR 類別之間的關係直接通過 AR 類別所代表的資料表之間的關係相關聯。從資料庫的角度來說,表 A 和 B 之間有三種關係:一對多(one-to-many,例如:tbl_user 和 tbl_post),一對一( one-to-one 例如:tbl_user 和 tbl_profile)和 多對多(many-to-many 例如:tbl_category 和 tbl_post)。
在 AR 中,有四種關係:
BELONGS_TO(屬於): 如果表 A 和 B 之間的關係是一對多,則 表 B 屬於 表 A (例如:Post屬於User);HAS_MANY(有多個): 如果表 A 和 B 之間的關係是一對多,則 A 有多個 B (例如:User有多個Post);HAS_ONE(有一個): 這是HAS_MANY的一個特例,A 最多有一個 B (例如:User最多有一個Profile);MANY_MANY: 這個對應於資料庫中的 多對多 關係。 由於多數 DBMS 不直接支援 多對多 關係,因此需要有一個關聯表將 多對多 關係分割為 一對多 關係。在我們的示例資料結構中,tbl_post_category就是用於此目的的。在 AR 術語中,我們可以解釋MANY_MANY為BELONGS_TO和HAS_MANY的組合。例如,Post屬於多個(belongs to many)Category,Category有多個(has many)Post.
AR 中定義關係需要覆蓋 CActiveRecord 中的 relations() 方法。此方法返回一個關係配置陣列。每個陣列元素通過如下格式表示一個單一的關係。
其中 VarName 是關係的名字;RelationType 指定關係類型,可以是一下四個常數之一:self::BELONGS_TO、self::HAS_ONE、self::HAS_MANY 和 self::MANY_MANY;ClassName 是此 AR 類別所關聯的 AR 類別的名字;ForeignKey 指定關係中使用的外鍵(一個或多個)。額外的選項可以在每個關係的最後指定(稍後詳述)。
以下程式碼示範了怎樣定義 User 和 Post 類別的關係:
訊息: 外鍵可能是復合的,包含兩個或更多個欄位。這種情況下,我們應該將這些外鍵名字鏈接,中間用空格或逗號分割。例如,
array('key1','key2')。這種情況下,必須指定自定的PK->FK關聯如array('fk'=>'pk')。至於複合鍵則是array('fk_c1'=>'pk_c1','fk_c2'=>'pk_c2')。對於MANY_MANY關係類型,關聯表的名字必須也必須在外鍵中指定。例如,Post中的categories關係由外鍵tbl_post_category(post_id, category_id)指定。
宣告 AR 類別中的關係,定義為每個關係向類別中隱含地增加了一個屬性。在一個關聯查詢執行後,相應的屬性將將被以關聯的 AR 實體填充。例如,如果 $author 代表一個 User AR 實體,我們可以使用 $author->posts 存取其關聯的 Post 實體。
執行關聯查詢
執行關聯查詢最簡單的方法是讀取一個 AR 實體中的關聯屬性。如果此屬性以前沒有被存取過,則一個關聯查詢將被初始化,它將兩個表關聯並使用當前 AR 實體的主鍵過濾。查詢結果將以所關聯 AR 類別的實體的方式保存到屬性中。這就是傳說中的 延遲載入 方式,例如,關聯查詢只在關聯的物件首次被存取時執行。下面的例子示範了怎樣使用這種方式:
訊息: 如果關係中沒有相關的實體,則相應的屬性將為 null 或一個空陣列。
BELONGS_TO和HAS_ONE關係的結果是 null,HAS_MANY和MANY_MANY的結果是一個空陣列。注意,HAS_MANY和MANY_MANY關係返回對像陣列,你需要在存取任何屬性之前先遍歷這些結果。否則,你可能會收到 "Trying to get property of non-object(嘗試存取非物件的屬性)" 錯誤。
延遲載入用起來很方便,但在某些情況下並不有效率。如果我們想獲取 N 個文章的作者,使用這種延遲載入將會導致執行 N 個關聯查詢。這種情況下,我們應該改為使用 渴求載入 方式。
渴求載入方式會在獲取主 AR 實體的同時獲取關聯的 AR 實體。這是通過在使用 AR 中的 find 或 findAll 方法時配合使用 with() 方法完成的。例如:
上述程式碼將返回一個 Post 實體的陣列。與延遲載入方式不同,在我們存取每個 Post 實體中的 author 屬性之前,它就已經被關聯的 User 實體填充了。
渴求載入通過一個 關聯查詢返回所有文章及其作者,而不是對每個文章執行一次關聯查詢。
我們可以在 with() 方法中指定多個關係名字,渴求載入將一次性全部取回他們。例如,如下程式碼會將文章連同其作者和分類別一併取回。
我們也可以實現內嵌的渴求載入。像下面這樣,我們傳遞一個分等級的關係名稱表達式到 with() 方法,而不是一個關係名稱列表:
上述例子將取回所有文章及其作者和所屬分類別。它還同時取回每個作者的簡介和文章。
渴求載入也可以通過指定 CDbCriteria::with 的屬性執行,就像下面這樣:
或者
不透過關聯模型進行關聯查詢
有時候我們需要使用關聯進行查詢,但不想要透過關聯模型。假設我們有 User 發表了許多 Post。文章可以被發佈,也可以被切換成草稿狀態。這是藉由文章模型中的 published 欄位來定義的。顯在我們需要取得所有有發表文章的使用者,且不想要與文章做交集。可以透過如下的方式完成:
關聯式查詢選項
我們提到在關係宣告時可以指定附加的選項。這些 名-值 配對形式的選項用於自定關聯式查詢。概括如下:
select: 關聯的 AR 類別中要選擇的欄位的列表。預設為 '*',即選擇所有欄位。此選項中的欄位名應該是已經消除歧義的。condition: 即WHERE條件。預設為空。此選項中的欄位名應該是已經消除歧義的。params: 要綁定到所產生的 SQL 語句的參數。應該以 名-值 配對陣列的形式賦值。on: 即ON語句。此處指定的條件將會通過AND操作符附加到 join 條件中。此選項中的欄位名應該是已經消除歧義的。此選項不會應用到MANY_MANY關係中。order: 即ORDER BY語句。預設為空。 此選項中的欄位名應該是已經消除歧義的。with: 一個需要被一起載入到這個物件的子物件列表。小心使用這個選項,不正確的使用會形成一個無限的關係迴圈。joinType: 關係的關聯類型。預設是LEFT OUTER JOIN。alias: 關係的別名。預設是 null,代表資料表別名與關係名稱一樣。together: 是否這個資料表相關的關係應該要強迫和主要資料表以及其他關聯在一起。這個選項只對HAS_MANY和MANY_MANY關係有意義。如果這個選項是 false,這個資料表HAS_MANY或MANY_MANY關係會以不同的 SQL 查詢與主要資料表關聯,可以提升整理個查詢效能藉由較少的重複資料被回傳。如果這個選項被設為 true,關聯的資料表會與主要資料關聯在單一一個 SQL 查詢,即使主要資料表已經被分頁。如果這個選項沒有被設定,關聯的資料表只會在主要資料被沒有被分頁時關聯在單一的 SQL 查詢。更詳細的內容,請參考 "Relational Query Performance" 章節。join: 額外JOIN子句。預設是空的。group:GROUP BY子句,預設是空的。欄位名應該是已經消除歧義的。having:HAVING子句。預設是空的。欄位名應該是已經消除歧義的。index: 值被用來儲存關聯物件陣列中的鑰匙的欄位名稱。沒有設定這個選項,一個關聯式的物件陣列會使用 0 開始的整數索引。這選項只會設定給HAS_MANYandMANY_MANY關係使用。
除此之外,下列的選項給延遲載入中的某些關係所使用:
limit: 指定要被選取的列的數量。這個選項無法使用在BELONGS_TO關係。offset: 指定要被選取的列的位移. 這個選項無法使用在BELONGS_TO關係。
下面我們修改了 posts 關係宣告給 User 藉由包含上述的一些項目:
如果我們現在存取 $author->posts,我們會得到作者的文章,並且以時間做降募的方式排序。每個文章實體也會載入他們的類別。
消除欄位名稱的歧義
當一個欄位名稱一起出現在兩個或更多的關聯表格,他需要被消除歧義。可以藉由前綴資料表的別名給這個欄位來完成。
在一個關聯式 AR 查詢,主要資料表的別名固定是 t,當一個關聯表格別名名稱是預設的關係名稱時。例如,下面的述句,別名名稱給 Post 和 Comment 分別是 t 和 comments:
現在假設兩個 Post 和 Comment 有一個欄位叫做 create_time 表示文章或是評論的建立時間,且我們想要取得文章和他的評論,並先以文章的建立時間來做排序,接著才是評論的建立時間。我們需要消除 create_time 欄位的歧義如下:
動態關聯式查詢選項
使用動態關聯是查詢在 with() 和 with 選項。動態的選項會覆寫現存 relations() 設定的選項。例如,上述的 User 模型,如果們想要使用渴求載入方法,來帶回一個作者的所有文章,而且是 升幕排序(order 選項在這個關係被指定成蔣慕排序),我們可以:
動態查詢選項也可以被使用在進行關聯查詢的延遲載入的方法中。要這麼做,我們必須要呼叫一個方法,他們名稱與關係的名稱相同,並且傳送給動態查詢選項當作方法參數。例如,下面的程式碼回傳一個使用者的文章的 status 是 1:
關聯式查詢效能
如上所述,渴求載入方法主要是用在需要存取許多關聯物件的情況。他會產生一個大且複雜的 SQL 述句藉由關聯所有的表格。在許多情況下,一個大的 SQL 述句是比較推崇的,他可以簡化一個欄位在關聯表格中的篩選。然而,他在某些情況下並不怎麼有效率。
考慮一個例子,當我們想要一起找出最新的文章和他的評論。假設每篇文章有 10 個評論,使用一個大 SQL 述句,我們會帶回許多冗餘資料,因為每篇文章會被每一個評論重複擁有。現在,試試其他方法:我們先查詢最新的文章,然後再查詢他的評論。在這個新方法中,我們需要執行兩個 SQL 述句。它的好處是沒有冗餘的東西在這個查詢結果。
所以,哪一種方法更有效率?沒有唯一的答案。執行一個大 SQL 述句可能會更有效率因為對 DBMS 造成較少的負擔在解析和執行。另一種情況,使用一個 SQL 述句,結果造成更多的冗餘資料和需要更多的時間來讀取和處理他們。
基於這個理由, Yii 提供了 together 查詢選項,使得可以在者兩個方法當中選擇我們需要的。預設,Yii 採用第一種方法,例如,產生一個 SQL 述句來進行渴求載入。我們可以設定 together 選項為 false 在關係的宣告,那某些表格就會藉分開的 SQL 述句關聯再一起。例如,為了使用第二種方法,查詢最新文章和評論,我們可以宣告 comments 關係在 Post 類別中如下,
當進行渴求載入時,我們也可以動態的設定這個選項:
統計查詢
除了上述的關聯查詢,Yii 也支援所謂的統計查詢(或聚合查詢)。他用來取得關聯物件的聚合資訊,像是每篇文章的評論數量、每樣產品的平均評價,等等。統計查詢可以只針對關聯中的物件進行, HAS_MANY(例如:一篇文章有許多評論)或 MANY_MANY (例如:一篇文章屬於許多類別和一個類別有許多文章)。
進行統計查詢跟前面所描述的關聯查詢非常的相似。首先,必須宣告統計查詢在 CActiveRecord 的 relations() 方法,就像我們在關聯查詢做的。
上述,我們宣告兩個統計查詢:commentCount 計算一篇文章的評論數量,和 categoryCount 計算一篇文章的類別數量。注意,Post 和 Comment 之間的關係是 HAS_MANY,而 Post 和 Category 之間的關係是 MANY_MANY(藉由關聯資表格 post_category)。如你所見,這個宣告跟前面的章節非常像。唯一不同的是關係類型在這裡是 STAT。
上述的宣告,我們可以取得一篇文章的評論數量藉由表達式 $post->commentCount。當我們第一次存取這個屬性,一個 SQL 述句會被隱含地執行來取得相應的結果。如我們已知的,這方法叫做 延遲載入。我們也可以使用 渴求載入 方法,如果我們需要定義許多文章的評論的數量: we need to determine the comment count for multiple posts:
上述述句會執行三個 SQL 來帶回所有文章以及他們的評論數量和類別數量。使用延遲載入方法,我們可以只使用 2*N+1 個 SQL 述句如果有 N 篇文章。
預設,一個統計查詢會計算 COUNT 表達式(和上述範例中的評論數量和類別數量)。當我們宣告 relations() 時,可以藉由設定額外的選項自定它。可使用的選項如下。
select: 統計表達式。預設是COUNT(*),表示計算子物件的數量。defaultValue: 用來賦予給那些沒有取得統計查詢結果的紀錄。例如,如果一篇文章沒有任何評論,它的commentCount會得到的這個值。這選項的預設值是 0。condition:WHERE子句。預設是空的。params: 用來綁定到產生的 SQL 述句的參數。它必須是一個 名-值 配對的陣列。order:ORDER BY子句。預設是空的。group:GROUP BY子句。預設是空的。having:HAVING子句。預設是空的。
命名空間的關聯查詢
關聯查詢可以與 named scopes 一起使用。有兩種形式,第一種,命名空間被用在主要的模型。第二個,命名空間被用在關聯模型。
下面的程式碼顯示如何應用命名空間在主要的模型。
這非常像非關聯查詢。唯一不同的是我們有 with() 的呼叫在命名空間串鍊。這個查詢會帶回最近發表的文章和評論。
下面的程式碼顯示如何應用命名空間到關聯模型。
上述的查詢會帶回所有文章和批准的評論。注意,comments 是指關係名稱,而 recently 和 approved 是指兩個宣告在 Comment 模型類別的命名空間。關係名稱和命名空間必須用分號隔開。
有時候你或許會需要使用延遲載入的方法取得一個空間的關聯性,除了上述一般的渴求載入方法。這種情況,下面的語法可以達到你要的:
~~ php // 注意,重複的關係名稱是必須的。 $approvedComments = $post->comments('comments:approved'); ~~
命名空間也可以被指定宣告在 CActiveRecord::relations() 關聯規則的 with 選項。下述的範例,如果我們存取 $user->posts,他會帶回文章所有 批准的 評論。
// 或 1.1.7 以後
注意: 命名空間應用在關聯模型必須在 CActiveRecord::scopes 指定。因此,他們不能被參數化。
從 1.1.7 以後,傳遞參數給關聯的命名空間是可行的。例如,如果你有空間命名為 rated 在 Post 中,用來允許最低的文章評分,你可以在 User 使用如下:
藉由 through 關聯查詢
當使用 through,關係的定義會像是:
上述 array('key1'=>'key2'):
key1是一個關係中的鍵,藉由指定through(本例中是posts)。key2是一個定義在模型中的鍵,指向(本例中Comment)。
through 可以同時與 HAS_ONE 和 HAS_MANY 關係使用。
HAS_MANY through
HAS_MANY through ER
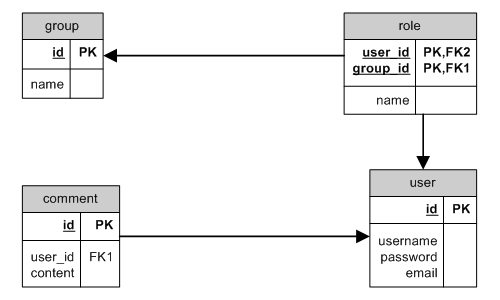
一個 HAS_MANY 和 through 的例子是,取得特定組群的使用者,當使用者是透過腳色賦予給組群時。
更複雜一點的例子是,取得特定族群所有的使用者的所有評論。這種情況下,我們必須使用多個關係和 through 在一個模型裡:
使用範例
HAS_ONE through
HAS_ONE through ER
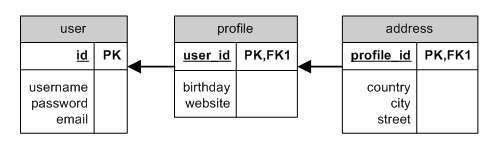
一個使用 HAS_ONE 和 through 的範例是從使用者綁定的個人資料中取得地址。所有的這些實體(使用者、個人資料和地址)有相應的模型:
使用範例
自身的 through
一個模型可以藉由一個橋接模型來綁定 through 給自己。例如,一個使用者教導其他使用者:
through self ER
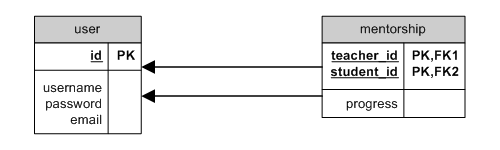
這情況的關係定義如下: